
Los cursos que indican "Vídeo" ya están (Tratamiento de datos, Estadística bayesiana, Aprendizaje Estadístico y Estadística No paramétrica) o estarán en las próximas semanas disponibles para poder tomarlos en su totalidad a través de vídeos. Sin embargo, para estos y todos los cursos, tenemos la opción presencial-virtual (sujeto a un cierto número de estudiantes por curso).
La información disponible por curso es: 1) Nombre del curso, 2) Descripción del curso, 3) Lo que serás capaz de realizar al finalizar el curso, 4) Descarga de temarios y 5) Información sobre dónde pueden obtenerse informes. Algunos cursos incluyen vídeo de una clase muestra o una explicación general del curso.
Si aún no estás inscrito a algún curso, el proceso para acceder a esta información desde esta página es:
- Dar click al curso de interés:

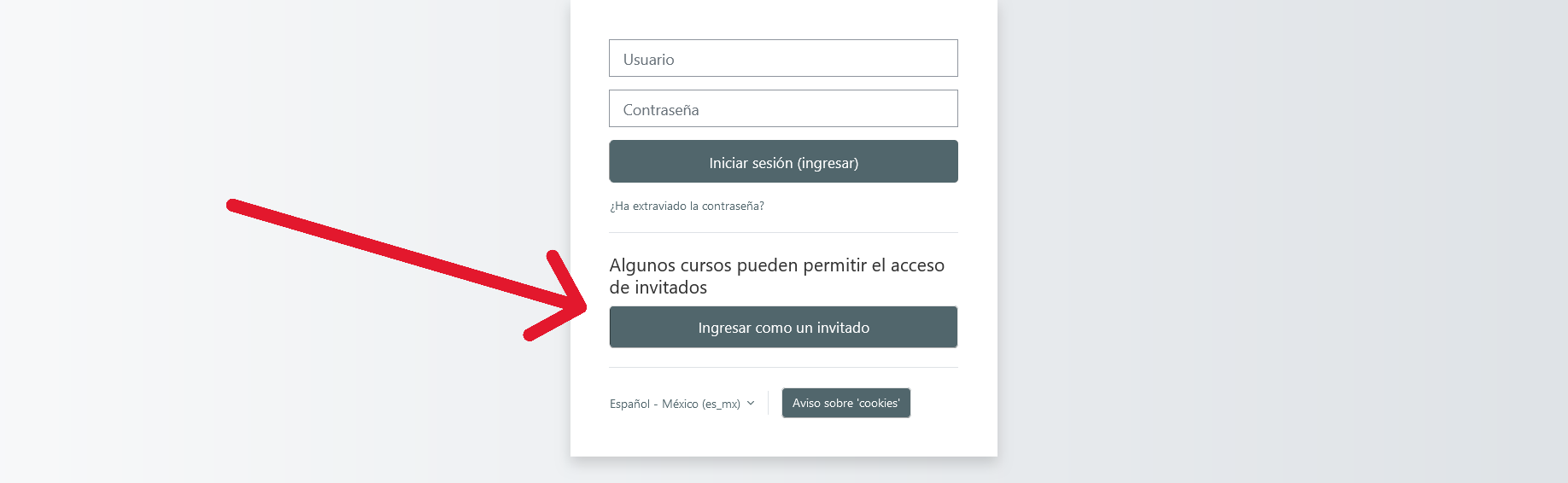
- Ingresa como invitado (si no se había ingresado antes):
- El temario está disponible antes de la de la sección Informes:

- Para ver más cursos y regresar a la página de inicio del sitio dar click a >Página principal del sitio y repetir el proceso (alternativamente puedes ingresar a >Mis cursos y luego a >Cursos para acceder a la información de cada curso o regresar a la página principal https://lumialearning.com/) :



























